
Another feature of a BTree index is the ability to reverse its keys. At first, you might ask yourself, “Why would I want to do that?” BTree indexes were designed for a specific environment and for a specific issue. They were implemented to reduce contention for index leaf blocks in “right-hand-side” indexes, such as indexes on columns populated by a sequence value or a timestamp, in an Oracle RAC environment.
Note We discussed RAC in Chapter 2.
RAC is a configuration of Oracle in which multiple instances can mount and open the same database. If two instances need to modify the same block of data simultaneously, they will share the block by passing it back and forth over a hardware interconnect, a private network connection between the two (or more) machines. If you have a primary key index on a column populated from a sequence (a very popular implementation), everyone will be trying to modify the one block that is currently the left block on the right-hand side of the index structure as they insert new values (see Figure 11-1, which shows that higher values in the index go to the right and lower values go to the left). Modifications to indexes on columns populated by sequences are focused on a small set of leaf blocks. Reversing the keys of the index allows insertions to be distributed across all the leaf blocks in the index, though it could tend to make the index much less efficiently packed.
Note You may also find reverse key indexes useful as a method to reduce contention, even in a single instance of Oracle. Again, you will mainly use them to alleviate buffer busy waits on the right-hand side of a busy index, as described in this section.
Before we look at how to measure the impact of a reverse key index, let’s discuss what a reverse key index physically does. A reverse key index simply reverses the bytes of each column in an index key. If we consider the numbers 90101, 90102, and 90103 and look at their internal representation using the Oracle DUMP function, we will find they are represented as follows:
SQL> select 90101, dump(90101,16) from dual union allselect 90102, dump(90102,16) from dual
Each one is 4 bytes in length and only the last byte is different. These numbers would end up right next to each other in an index structure. If we reverse their bytes, however, Oracle will insert the following:
90101 reversed = 2,2,a,c3
90102 reversed = 3,2,a,c3
90103 reversed = 4,2,a,c3
The numbers will end up far away from each other. This reduces the number of RAC instances going after the same block (the rightmost block) and reduces the number of block transfers between RAC instances. One of the drawbacks to a reverse key index is that you cannot use it in all cases where a regular index can be applied. For example, in answering the following predicate, a reverse key index on X would not be useful:
where x > 5
The data in the index is not sorted by X before it is stored, but rather by REVERSE(X); hence, the range scan for X > 5 will not be able to use the index. On the other hand, some range scans can be done on a reverse key index. If I have a concatenated index on (X, Y), the following predicate will be able to make use of the reverse key index and will range scan it:
where x = 5
This is because the bytes for X are reversed, and then the bytes for Y are reversed. Oracle does not reverse the bytes of (X || Y), but rather stores (REVERSE(X) || REVERSE(Y)). This means all of the values for X = 5 will be stored together, so Oracle can range scan that index to find them all.
Now, assuming you have a surrogate primary key on a table populated via a sequence, and you do not need to use range scanning on this index—that is, you don’t need to query for MAX(primary_key), MIN(primary_key), WHERE primary_key < 100, and so on—then you could consider a reverse key index in high insert scenarios even in a single instance of Oracle.
I set up a test in a PL/SQL environment to demonstrate the differences between inserting into a table with a reverse key index on the primary key and one with a conventional index. The table used was created with the following DDL:
$ sqlplus eoda/foo@PDB1
SQL> create tablespace assmdatafile size 1m autoextend on next 1m segment space management auto;
SQL> alter table t add constraint t_pk primary key (id)using index (create index t_pk on t(id) &indexType tablespace assm);
SQL> create sequence s cache 1000;
whereby &indexType was replaced with either the keyword REVERSE, creating a reverse key index, or with nothing, thus using a “regular” index. The PL/SQL that would be run by 1, 2, 5, 10, 15, or 20 users concurrently was as follows:
SQL> create or replace procedure do_sql as begin for x in ( select rownum r, OWNER, OBJECT_NAME, SUBOBJECT_NAME,OBJECT_ID, DATA_OBJECT_ID, OBJECT_TYPE, CREATED, LAST_DDL_TIME
Tip You can download the source code for the reverse key index performance example from the GitHub website. In the Chapter 11 scripts folder, there are several demo3* files that automate the running of this entire test suite.
The following tables summarize the differences between the various runs, starting with the single user test in Table 11-1.
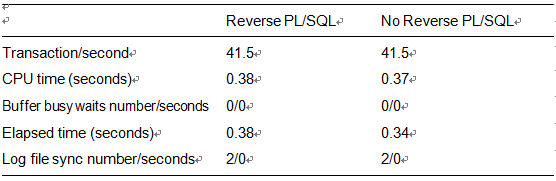
Table 11-1. Performance Test for Use of Reverse Key Indexes with PL/SQL: Single User Case
It would appear from this single-user test that reverse key indexes consume slightly more CPU. This makes sense because the database must perform extra work as it carefully reverses the bytes in the key. But we’ll see that this logic won’t hold true as we scale up the users. As we introduce contention, the overhead of the reverse key index will completely disappear. In fact, even by the time we get the two-user test, the overhead is mostly offset by the contention on the right-hand side of the index, as shown in Table 11-2.
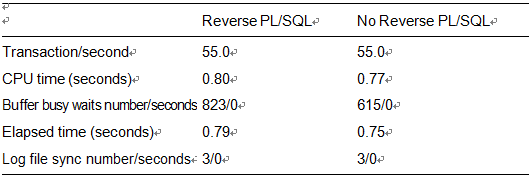
Table 11-2. Performance Test for Use of Reverse Key Indexes with PL/SQL: Two Users
Let’s move on to the five-user test, shown in Table 11-3.
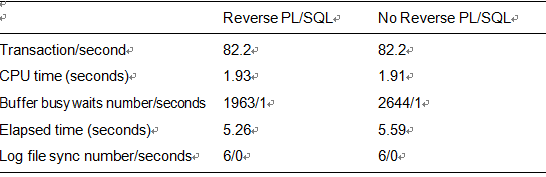
Table 11-3. Performance Test for Use of Reverse Key Indexes with PL/SQL: Five Users
We see more of the same. PL/SQL, running full steam ahead with few log file sync waits, was very much impacted by the buffer busy waits. With a conventional index and all five users attempting to insert into the right-hand side of the index structure, PL/SQL suffered the most from the buffer busy waits and therefore benefited the most when they were reduced.
Taking a look at the ten-user test in Table 11-4, we can see the trend continues.
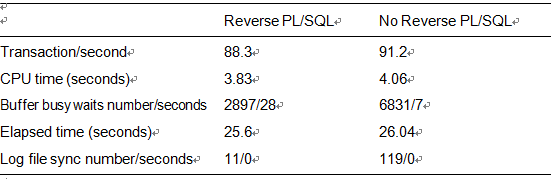
Table 11-4. Performance Test for Use of Reverse Key Indexes with PL/SQL: Ten Users
PL/SQL, in the absence of the log file sync wait, is very much helped by removing the buffer busy wait events. One way to improve the performance of the PL/SQL implementation with a regular index would be to introduce a small wait. That would reduce the contention on the right-hand side of the index and increase overall performance. For space reasons, I will not include the 15- and 20-user tests here, but I will confirm that the trend observed in this section continued.
We can take away two things from this demonstration. A reverse key index can help alleviate a buffer busy wait situation, but depending on other factors, you will get varying returns on investment. In looking at Table 11-4 for the ten-user test, the removal of buffer busy waits (the most waited for the wait event in that case) affected transaction throughput marginally, but it did show increased scalability with higher concurrency levels.