
This table introduces a new option, PCTTHRESHOLD, which we’ll look at in a moment. You might have noticed that something is missing from the preceding CREATE TABLE syntax: there is no PCTUSED clause, but there is a PCTFREE. This is because an index is a complex data structure that isn’t randomly organized like a heap, so data must go where it belongs. Unlike a heap, where blocks are sometimes available for inserts, blocks are always available for new entries in an index. If the data belongs on a given block because of its values, it will go there regardless of how full or empty the block is. Additionally, PCTFREE is used only when the object is created and populated with data in an index structure. It is not used like it is in the heap-organized table. PCTFREE will reserve space on a newly created index, but not for subsequent operations on it. The same considerations for FREELISTs we had on heap-organized tables apply in whole to IOTs.
First, let’s look at the NOCOMPRESS option. This option is different in implementation from the table compression discussed earlier. It works for any operation on the index- organized table (as opposed to the table compression which may or may not be in effect for conventional path operations). Using NOCOMPRESS, it tells Oracle to store each and every value in an index entry (i.e., do not compress). If the primary key of the object were on columns A, B, and C, every occurrence of A, B, and C would physically be stored. The converse to NOCOMPRESS is COMPRESS N, where N is an integer that represents the number of columns to compress. This removes repeating values and factors them out at the block level, so that the values of A and perhaps B that repeat over and over are no longer physically stored. Consider, for example, a table created like this:
SQL> create table iot( owner, object_type, object_name,primary key(owner,object_type,object_name))
It you think about it, the value of OWNER is repeated many hundreds of times. Each schema (OWNER) tends to own lots of objects. Even the value pair of OWNER, OBJECT_TYPE repeats many times, so a given schema will have dozens of tables, dozens of packages, and so on. Only all three columns together do not repeat. We can have Oracle suppress these repeating values. Instead of having an index block with values shown in Table 10-1, we could use COMPRESS 2 (factor out the leading two columns) and have a block with the values shown in Table 10-2.
Table 10-1. Index Leaf Block, NOCOMPRESS

Table 10-2. Index Leaf Block, COMPRESS 2

That is, the values SYS and TABLE appear once, and then the third column is stored. In this fashion, we can get many more entries per index block than we could otherwise. This does not decrease concurrency—we are still operating at the row level in all cases— or functionality at all. It may use slightly more CPU horsepower, as Oracle has to do more work to put together the keys again. On the other hand, it may significantly reduce I/O and allow more data to be cached in the buffer cache, since we get more data per block. That is a pretty good tradeoff.
Let’s demonstrate the savings by doing a quick test of the preceding CREATE TABLE as SELECT with NOCOMPRESS, COMPRESS 1, and COMPRESS 2. We’ll start by creating our IOT without compression:
SQL> create table iot( owner, object_type, object_name,constraint iot_pk primary key(owner,object_type,object_name))
Now we can measure the space used. We’ll use the ANALYZE INDEX VALIDATE STRUCTURE command for this. This command populates a dynamic performance view named INDEX_STATS, which will contain only one row at most with the information from the last execution of that ANALYZE command:
SQL> analyze index iot_pk validate structure; Index analyzed.
SQL> select lf_blks, br_blks, used_space, opt_cmpr_count, opt_cmpr_pctsave
This shows our index is currently using 240 leaf blocks (where our data is) and 1 branch block (blocks Oracle uses to navigate the index structure) to find the leaf blocks. The space used is about 1.7MB (1,726,727 bytes). The other two oddly named columns are trying to tell us something.
The OPT_CMPR_COUNT (optimum compression count) column is trying to say, “If you made this index COMPRESS 2, you would achieve the best compression.” The OPT_CMPR_PCTSAVE (optimum compression percentage saved) is telling us if we did the COMPRESS 2, we would save about one-third of the storage, and the index would consume just two-thirds the disk space it is now.
As you can see, the index is in fact smaller: about 1.5MB, with fewer leaf blocks. But now it is saying, “You can still get another 28 percent off,” as we didn’t chop off that much yet. Let’s rebuild with COMPRESS 2:
SQL> alter table iot move compress 2;Table altered.
SQL> analyze index iot_pk validate structure; Index analyzed.
Now we are significantly reduced in size, both by the number of leaf blocks and overall used space, by about 1MB. If we go back to the original numbers
SQL> select (1-.37)* 1726727 from dual;
we can see the OPT_CMPR_PCTSAVE was pretty much dead-on. The preceding example points out an interesting fact with IOTs. They are tables, but only in name. Their segment is truly an index segment.
I am going to defer discussion of the PCTTHRESHOLD option at this point, as it is related to the next two options for IOTs: OVERFLOW and INCLUDING. If we look at the full SQL for the next two sets of tables, T2 and T3, we see the following (I’ve used a DBMS_METADATA routine to suppress the storage clauses, as they are not relevant to the example):
SQL> begindbms_metadata.set_transform_param
So, now we have PCTTHRESHOLD, OVERFLOW, and INCLUDING left to discuss. These three items are intertwined, and their goal is to make the index leaf blocks (the blocks that hold the actual index data) able to efficiently store data. An index is typically on a subset of columns. You will generally find many more times the number of row entries on an index block than you would on a heap table block. An index counts on being able to get many rows per block. Oracle would spend large amounts of time maintaining an index otherwise, as each INSERT or UPDATE would probably cause an index block to split in order to accommodate the new data.
The OVERFLOW clause allows you to set up another segment (making an IOT a multisegment object, much like having a CLOB column does) where the row data for the IOT can overflow onto when it gets too large.
Note The columns making up the primary key cannot overflow—they must be placed on the leaf blocks directly.
Notice that an OVERFLOW reintroduces the PCTUSED clause to an IOT. PCTFREE and PCTUSED have the same meanings for an OVERFLOW segment as they do for a heap-organized table. The conditions for using an overflow segment can be specified in one of two ways:
•\ PCTTHRESHOLD: When the amount of data in the row exceeds that percentage of the block, the trailing columns of that row will be stored in the overflow. So, if PCTTHRESHOLD was ten percent and your block size was 8KB, any row that was greater than about 800 bytes in length would have part of it stored elsewhere, off the index block.
•\ INCLUDING: All of the columns in the row up to and including the one specified in the INCLUDING clause are stored on the index block, and the remaining columns are stored in the overflow.
Graphically, it could look like Figure 10-6.
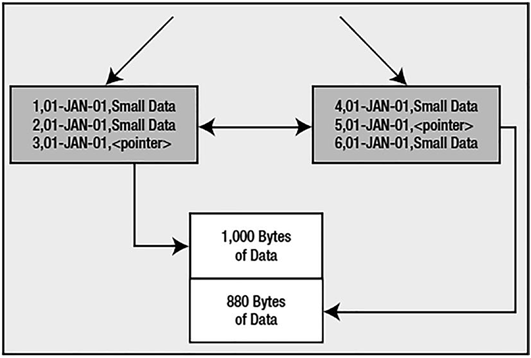
Figure 10-6. IOT with overflow segment, PCTTHRESHOLD clause
The gray boxes are the index entries, part of a larger index structure (in Chapter 11, you’ll see a larger picture of what an index looks like). Briefly, the index structure is a tree, and the leaf blocks (where the data is stored) are, in effect, a doubly linked list to make it easier to traverse the nodes in order once we’ve found where we want to start in the index.
The white box represents an OVERFLOW segment. This is where data that exceeds our PCTTHRESHOLD setting will be stored. Oracle will work backward from the last column up to but not including the last column of the primary key to find out what columns need to be stored in the overflow segment. In this example, the number column X and the date column Y will always fit in the index block.
The last column, Z, is of varying length. When it is less than about 190 bytes or so (10 percent of a 2KB block is about 200 bytes; subtract 7 bytes for the date and 3 to 5 for the number), it will be stored on the index block. When it exceeds 190 bytes, Oracle will store the data for Z in the overflow segment and set up a pointer (a rowid, in fact) to it.
The other option is to use the INCLUDING clause. Here, we are stating explicitly what columns we want stored on the index block and which should be stored in the overflow. Given a CREATE TABLE statement like this:
SQL> create table iot
( x int,y date,z varchar2(2000),constraint iot_pk primary key (x))
what we can expect to find is illustrated in Figure 10-7.
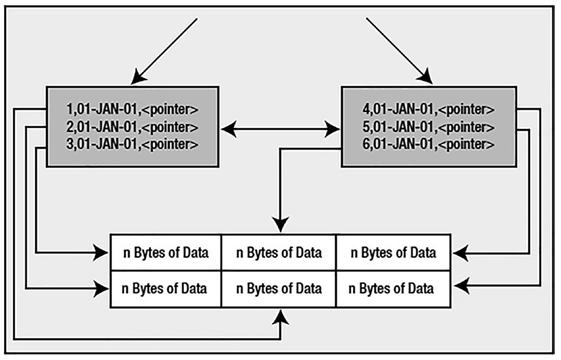
Figure 10-7. IOT with OVERFLOW segment, INCLUDING clause
In this situation, regardless of the size of the data stored in it, Z will be stored out of line in the overflow segment (all nonprimary key columns that follow the column specified in the INCLUDING clause are stored in the overflow segment).
Which is better then: PCTTHRESHOLD, INCLUDING, or some combination of both? It depends on your needs. If you have an application that always, or almost always, uses the first four columns of a table and rarely accesses the last five columns, using INCLUDING would be appropriate. You would include up to the fourth column and let the other five be stored out of line.
At runtime, if you need them, the columns will be retrieved in much the same way as a chained row would be. Oracle will read the head of the row, find the pointer to the rest of the row, and then read that. If, on the other hand, you cannot say that you almost always access these columns and hardly ever access those columns, you should give some consideration to PCTTHRESHOLD. Setting PCTTHRESHOLD is easy once you determine the number of rows you would like to store per index block on average. Suppose you wanted 20 rows per index block.
Well, that means each row should be one-twentieth (five percent). Your PCTTHRESHOLD would be five, and each chunk of the row that stays on the index leaf block should consume no more than five percent of the block.
The last thing to consider with IOTs is indexing. You can have an index on IOTs themselves—sort of like having an index on an index. These are called secondary indexes. Normally, an index contains the physical address of the row it points to, the rowid. An IOT secondary index cannot do this; it must use some other way to address the row.
This is because a row in an IOT can move around a lot, and it does not migrate in the way a row in a heap-organized table would. A row in an IOT is expected to be at some position in the index structure, based on its primary key value; it will only be moving because the size and shape of the index itself are changing. (We’ll cover more about how index structures are maintained in the next chapter.) To accommodate this, Oracle introduced a logical rowid.
These logical rowids are based on the IOT’s primary key. They may also contain a guess as to the current location of the row, although this guess is almost always wrong because after a short while, data in an IOT tends to move. The guess is the physical address of the row in the IOT when it was first placed into the secondary index structure. If the row in the IOT has to move to another block, the guess in the secondary index becomes stale.
Therefore, an index on an IOT is slightly less efficient than an index on a regular heap-organized table. On a regular table, an index access typically requires the I/O to scan the index structure and then a single read to read the table data. With an IOT, typically two scans are performed: one on the secondary structure and the other on the IOT itself. That aside, indexes on IOTs provide fast and efficient access to the data in the IOT using columns other than the primary key.